Jeg har for en periode jobbet med en simuleringsmodell, som et tillegg til @Polygon sin modell for fordeling av events og avlesningstidspunkter av INITIUM. Ble oppfordret i tidligere i dag til å legge ut en liten teaser før hovedinnlegget.
Helt kort: Modellen er basert på PFS for Kaplan Meier plottet fra Checkmate-067, med hazard ratio som input. Ved å gjøre mange nok simuleringer med forskjellig hazard ratio, får man da et bredt utvalg med simuleringer, slik at man kan filtrere på forskjellige scenarioer basert på effekt.
Her er en tabell, der mPFS i utgangspunktet er 8.7 mnd altså en betydelig sykere kontrollarm og helt i nedre sjikt av konfidensintervallet fra Checkmate – 067, der mPFS var 11.5 mnd:
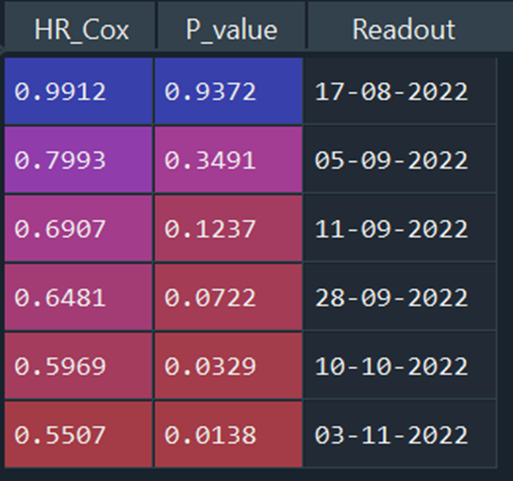
Datagrunnlaget for denne populasjonen er litt tynt, og verdiene er beregnet på noen filtreringer f.eks 3 mnd PFS, 6 mnd PFS, mPFS der dette faktisk nås og ikke minst hazard ratio. Verdiene i hver kolonne er beregnet ved å ta medianen i hver av dem, radvis, etter filtreringene. En rad representer derfor ikke et Kaplan Meier plot nødvendigvis. Og vær litt kritisk til disse avlesningstidspunktene, det er et tynt datagrunnlag, noe man nesten kan se basert på den varierende avstanden i avlesningsdatoer sammenlignet med p-verdi og hazard ratio.
Her er et Kaplan Meier plot for et slikt tilfelle som det nest nederste i tabellen, altså statistisk signifikant med god margin:
Her er det ganske stor forskjell i avlesningsdatoene for plottet og nest nederste rad i tabellen, for ganske lik hazard ratio og p-verdi. Det illustrerer visse usikkerheter. Det er forøvrig samme Kaplan Meier plot som jeg la ut i biotekchatten på søndag.
Noen ordforklaringer:
mPFS_C: Median Progression-free survival for kontrollarmen.
CI_l og CI_U: Nedre og øvre 95% konfidensintervall
HR_Cox: Hazard ratio beregnet med Cox proportional hazards model:
P_value: P-verdi beregnet med Log Rank test
Readout: Avlesningsdato, altså 31.oktober i år for dette spesifikke tilfellet.
Det kommer et mye lengre og detaljert innlegg om en ukes tid, med mange flere plot for forskjellige scenarioer, så eventuelle spørsmål rundt teori, metode, resultater osv. besvares forhåpentligvis bedre da.






